Plagiarism candidate retrieval using selective query formulation and discriminative query scoring: Notebook for PAN at CLEF 2013
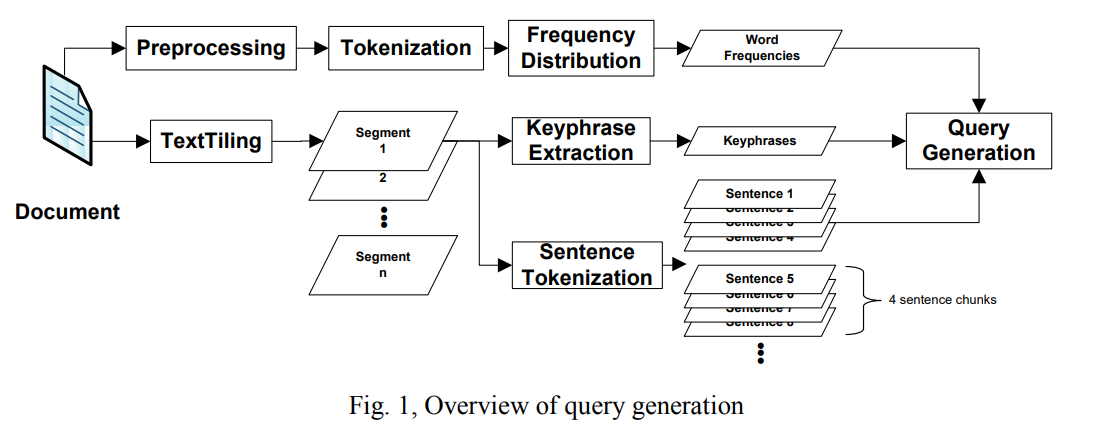
This paper details the approach of implementing an English plagiarism source retrieval system to be presented at PAN 2013. The system uses the TextTiling algorithm to break a given document into segments that are centered around certain topics within the document. From these segments, keyphrases are generated using the KPMiner keyphrase extraction system. These keyphrases and segments are then used in generating queries indicative of the segment, and consequently the document. The queries are submitted to ChatNoir for finding plagiarism sources in the ClueWeb09 corpus from which the pan13 dataset is plagiarized. The target is to lessen the overall search effort while maximizing the performance by scoring unconsumed queries against the already downloaded candidate sources. Comparison to other PAN 2013 submissions for the same task, show the presented system to be one of the top performers.
Related Publications

Hands-on analysis of using large language models for the auto evaluation of programming assignments