


High Speed, Approximate Arithmetic Based Convolutional Neural Network Accelerator
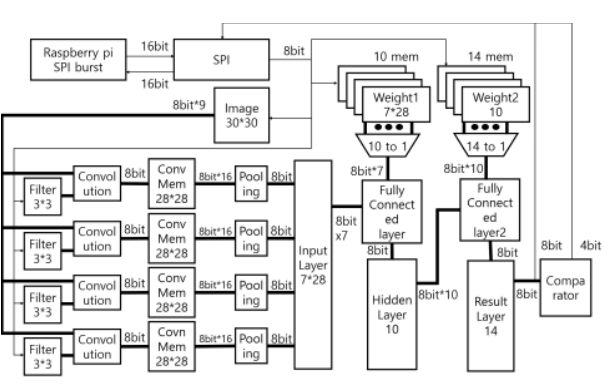
Convolutional Neural Networks (CNNs) for Artificial Intelligence (AI) algorithms have been widely used in many applications especially for image recognition. However, the growth in CNN-based image recognition applications raised challenge in executing millions of Multiply and Accumulate (MAC) operations in the state-of-The-Art CNNs. Therefore, GPUs, FPGAs, and ASICs are the feasible solutions for balancing processing speed and power consumption. In this paper, we propose an efficient hardware architecture for CNN that provides high speed, low power, and small area targeting ASIC implementation of CNN accelerator. To realize low cost inference accelerator. we introduce approximate arithmetic operators for MAC operators, which comprise the key datapath components of CNNs. The proposed accelerator architecture exploits parallel memory access, and N-way high speed and approximate MAC units in the convolutional layer as well as the fully connected layers. Since CNNs are tolerant to small error due to the nature of convolutional filters, the approximate arithmetic operations incur little or no noticeable loss in the accuracy of the CNN, which we demonstrate in our test results. For the approximate MAC unit, we use Dynamic Range Unbiased Multiplier (DRUM) approximate multiplier and Approximate Adder with OR operations on LSBs (AOL) which can substantially reduce the chip area and power consumption. The configuration of the approximate MAC units within each layer affects the overall accuracy of the CNN. We implemented various configurations of approximate MAC on an FPGA, and evaluated the accuracy using an extended MNIST dataset. Our implementation and evaluation with selected approximate MACs demonstrate that the proposed CNN Accelerator reduces the area of CNN by 15% at the cost of a small accuracy loss of only 0.982% compared to the reference CNN. © 2020 IEEE.
Related Publications

Hands-on analysis of using large language models for the auto evaluation of programming assignments


