


NGU_CNLP at WANLP 2022 Shared Task: Propaganda Detection in Arabic
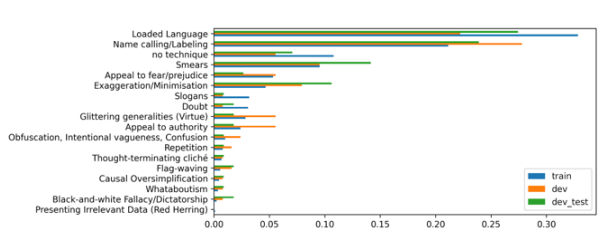
This paper presents the system developed by the NGU_CNLP team for addressing the shared task on Propaganda Detection in Arabic at WANLP 2022. The team participated in the shared tasks' two sub-tasks which are: 1) Propaganda technique identification in text and 2) Propaganda technique span identification. In the first sub-task the goal is to detect all employed propaganda techniques in some given piece of text out of a possible 17 different techniques, or to detect that no propaganda technique is being used in that piece of text. As such, this first sub task is a multi-label classification problem with a pool of 18 possible labels. Subtask 2 extends subtask 1, by requiring the identification of the exact text span in which a propaganda technique was employed, making it a sequence labeling problem. For task 1, a combination of a data augmentation strategy coupled with an enabled transformer-based model, comprised our classification model. This classification model ranked first amongst the 14 systems participating in this subtask. For subtask two, a transfer learning model was adopted. The system ranked third among the 3 different models that participated in this subtask. © 2022 Association for Computational Linguistics.
Related Publications

Hands-on analysis of using large language models for the auto evaluation of programming assignments


