


In the Identification of Arabic Dialects: A Loss Function Ensemble Learning Based-Approach
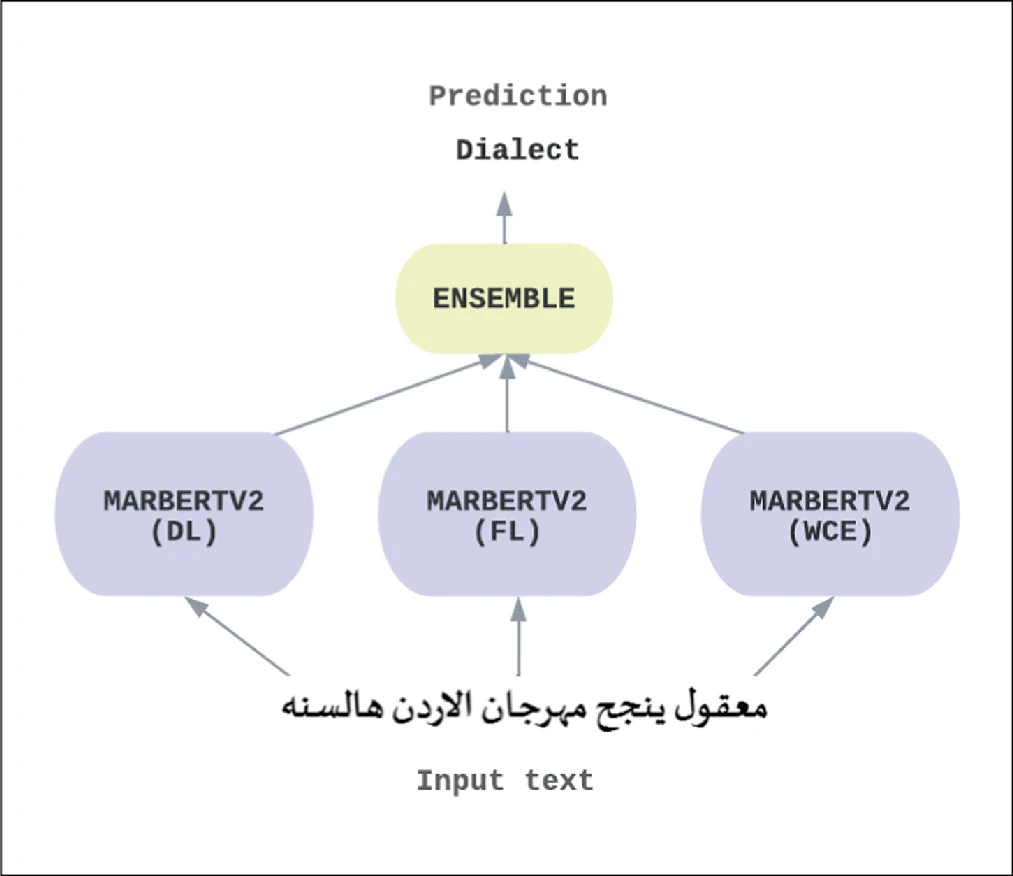
The automation of a system to accurately identify Arabic dialects many natural language processing tasks, including sentiment analysis, medical chatbots, Arabic speech recognition, machine translation, etc., will greatly benefit because it’s useful to understand the text’s dialect before performing different tasks to it. Different Arabic-speaking nations have adopted various dialects and writing systems. Most of the Arab countries understand modern standard Arabic (MSA), which is the native language of all other Arabic dialects. In this paper we propose a method for identifying Arabic dialects Using the Arabic Online Commentary dataset (AOC), which includes three Arabic dialects-Gulf, Levantine, and egyptian-alongside MSA. Our approach includes two ensemble learning strategies using two BERT-based models and different loss functions such as focal loss, dice loss, and weighted cross-entropy loss. The first strategy is between the two proposed models using the loss function that performed best on the models, and the other is between the same model but using different loss functions, which resulted in 83.3%, 80.1%, 85.8%, 81.45%, Precision, Recall, Accuracy and Macro-F1 on the test set respectively. © 2023, The Author(s), under exclusive license to Springer Nature Switzerland AG.
Related Publications

Hands-on analysis of using large language models for the auto evaluation of programming assignments


