


Towards Intelligent Web Context-Based Content On-Demand Extraction Using Deep Learning
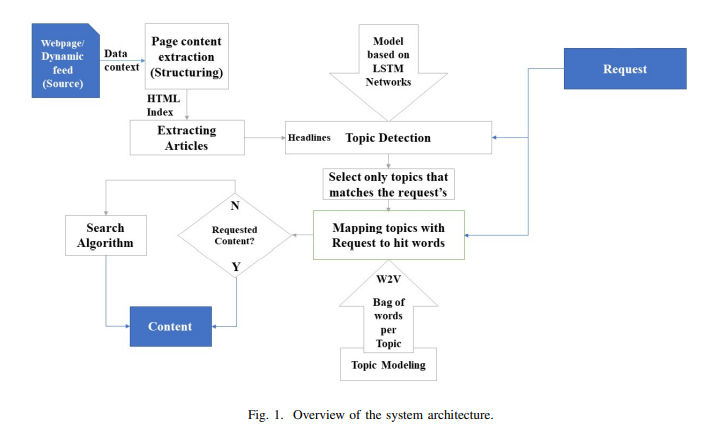
Information extraction and reasoning from massive high-dimensional data at dynamic contexts, is very demanding and yet is very hard to obtain in real-time basis. However, such process capability and efficiency might be affected and limited by the available computational resources and the consequent power consumption. Conventional search mechanisms are often incapable of real-time fetching a predefined content from data source, without concerning the increased number of connected devices that contribute to the same source. In this work, we propose and present a concept for an efficient approach for online content searching, takes advantage of a) the structure of data profiling employed at the related data source; and b) the learning algorithms that are used for extracting its common features and for generating a map of indices to data contents. This enables instant mapping of users requests to make the process as realtime as possible. The adopted learning algorithms main blocks are built to capture the semantic features in the targeted context of data sentences. We reviewed several learning approaches and compared their results based on the criteria of capturing the semantic features that appeared through the preliminary results. The preliminary results conclusively confirmed that employing the weighted recurrent neural networks and the GloVE pre-trained model paired with NMF topic modeling, yielded highly acceptable levels of Fl-score and prediction time. © 2020 IEEE.
Related Publications

Hands-on analysis of using large language models for the auto evaluation of programming assignments


