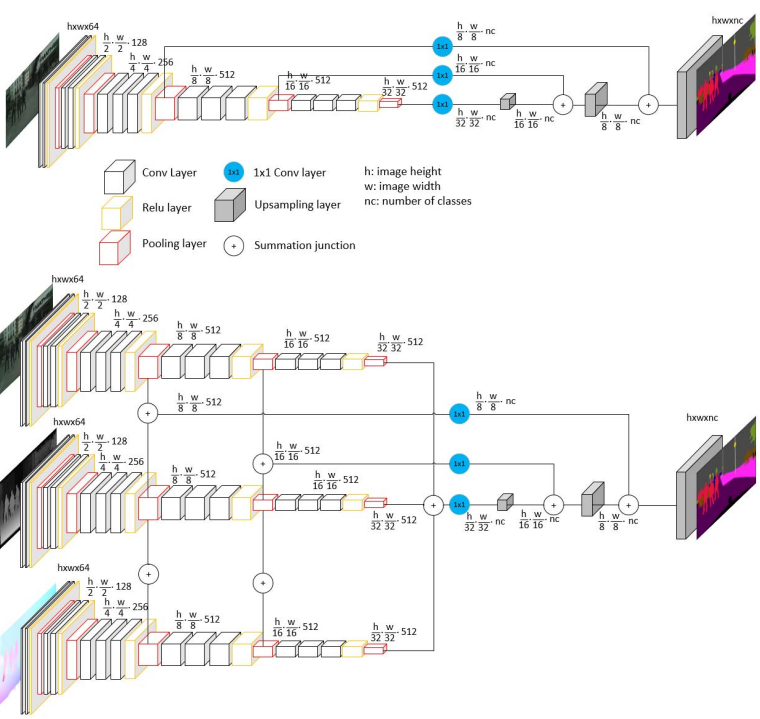
Motion and depth augmented semantic segmentation for autonomous navigation
Motion and depth provide critical information in autonomous driving and they are commonly used for generic object detection. In this paper, we leverage them for improving semantic segmentation. Depth cues can be useful for detecting road as it lies below the horizon line. There is also a strong structural similarity for different instances of different objects including buildings and trees. Motion cues are useful as the scene is highly dynamic with moving objects including vehicles and pedestrians. This work utilizes geometric information modelled by depth maps and motion cues represented by optical flow vectors to improve the pixel-wise segmentation task. A CNN architecture is proposed and the variations regarding the stage at which color, depth, and motion information are fused, e.g. early-fusion or mid-fusion, are systematically investigated. Additionally, we implement a multimodal fusion algorithm to maximize the benefit from all the information. The proposed algorithms are evaluated on Virtual-KITTI and Cityscapes datasets where results demonstrate enhanced performance with depth and flow augmentation. © 2019 IEEE.
Related Publications

Hands-on analysis of using large language models for the auto evaluation of programming assignments